Publications/Reports

We tackle 3D hand–object pose estimation in unconstrained, cluttered, occluded egocentric video. We contribute EPIC-Contact, an in-the-wild dataset with dense bijective 3D hand–object contact, and HOPformer, a transformer that conditions object pose on strong hand priors to predict both hands and the object in a single forward pass.
Siddhant Bansal, Zhifan Zhu, Shashank Tripathi, Jiahe Zhao, Michael Black, Dima Damen
European Conference on Computer Vision (ECCV), 2026
Paper (ArXiv) / Project Page / Code / Download EPIC-Contact / Download Checkpoints
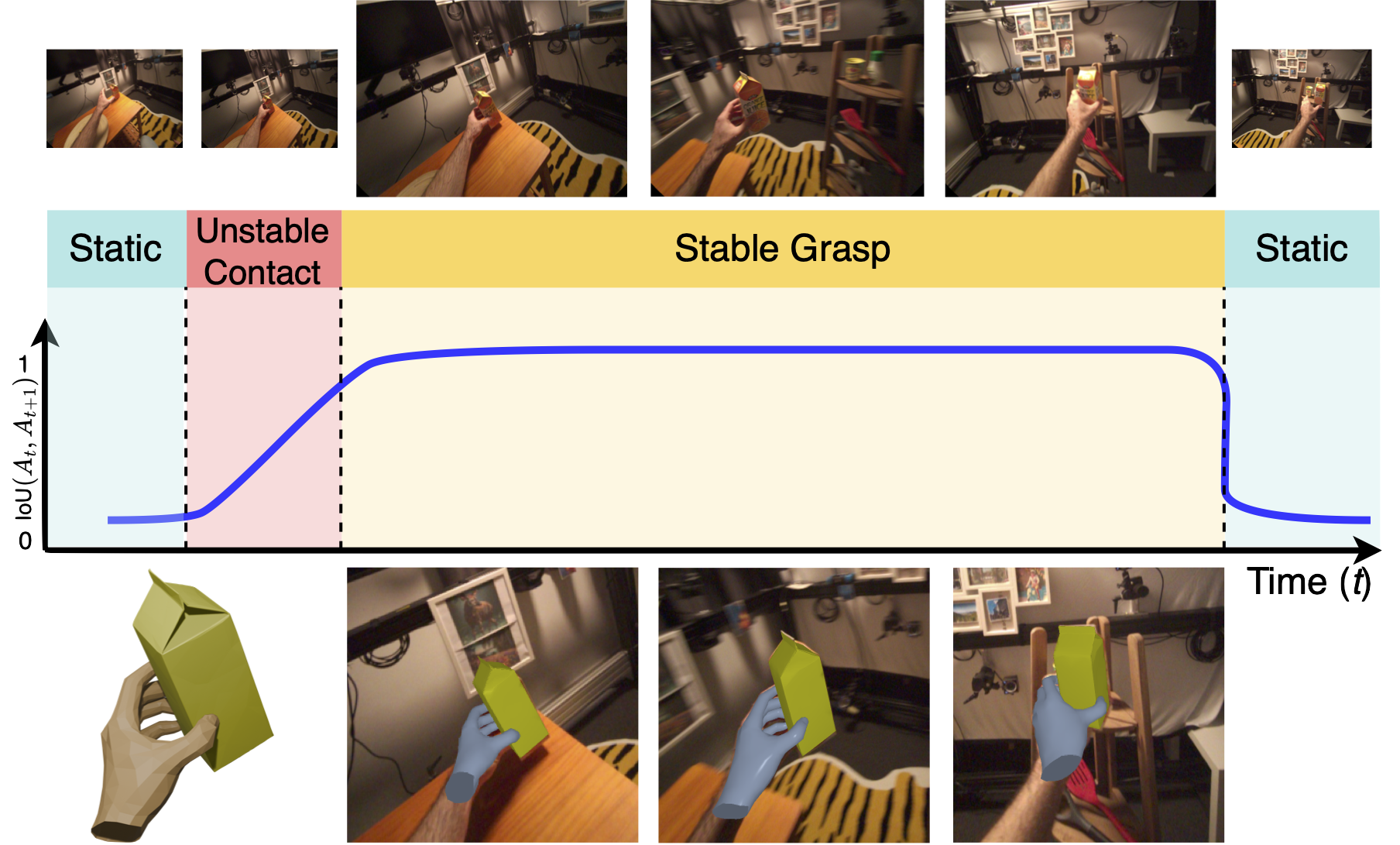
A constrained optimisation framework that reconstructs object poses in egocentric video by modelling temporal constraints, from static to stably grasped.
Zhifan Zhu, Siddhant Bansal, Shashank Tripathi, Dima Damen
Conference on Computer Vision and Pattern Recognition’s SaS Workshop (CVPR-W), 2026
Paper (ArXiv) / Project Page / Code / Qualitative Results Video
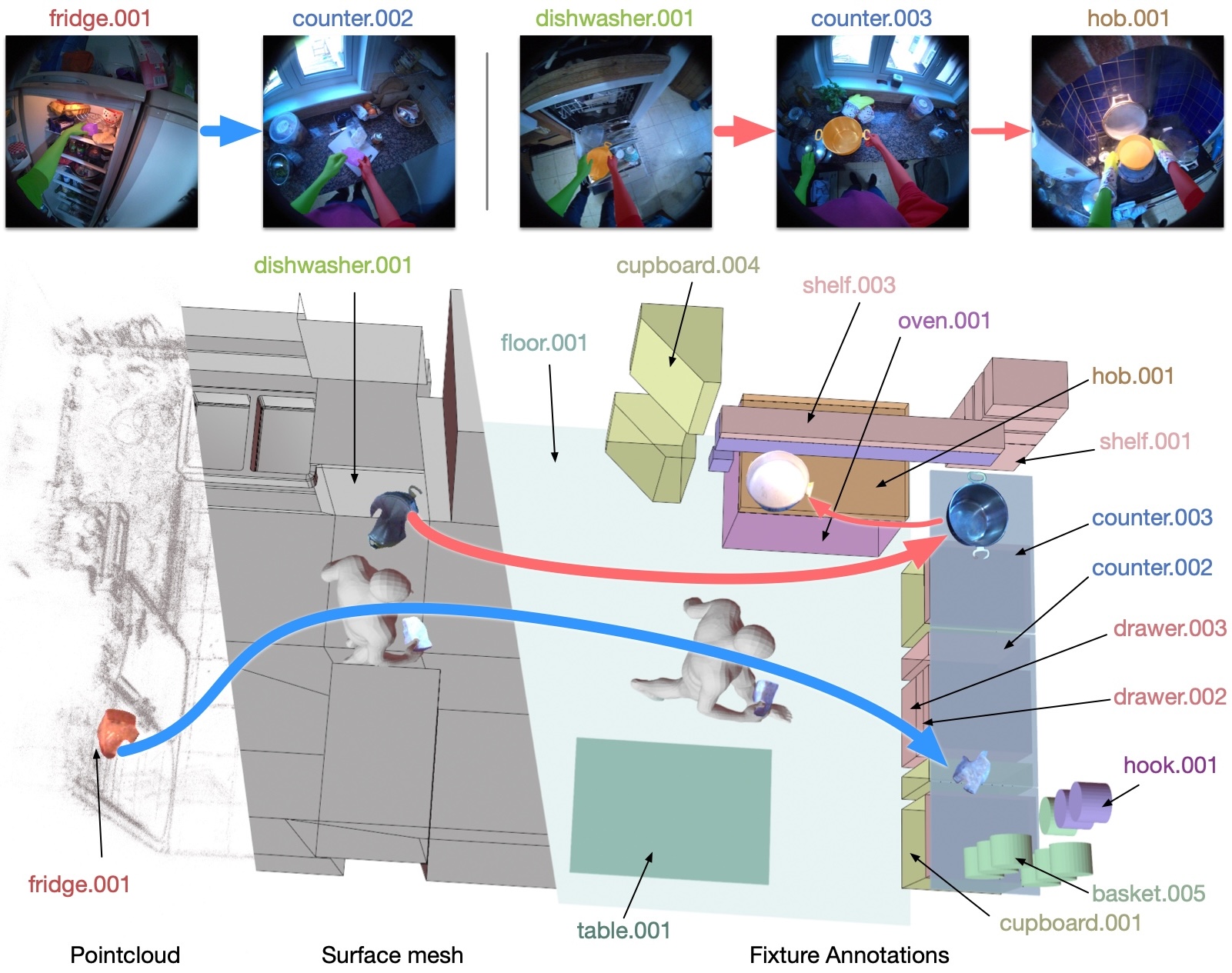
A validation dataset of kitchen-based egocentric videos with detailed, interconnected annotations on recipe steps, actions, ingredients, objects, audio, and 3D-grounded scene elements via digital twinning and gaze. Annotations include nutritional values, object locations, and fixture details.
Toby Perrett, Ahmad Darkhalil, Saptarshi Sinha, Omar Emara, Sam Pollard, Kranti Parida, Kaiting Liu, Prajwal Gatti, Siddhant Bansal, Kevin Flanagan, Jacob Chalk, Zhifan Zhu, Rhodri Guerrier, Fahd Abdelazim, Bin Zhu
Conference on Computer Vision and Pattern Recognition (CVPR), 2025
Paper (ArXiv) / Project Page / Download HD-EPIC / Explore Samples / Video (YouTube)
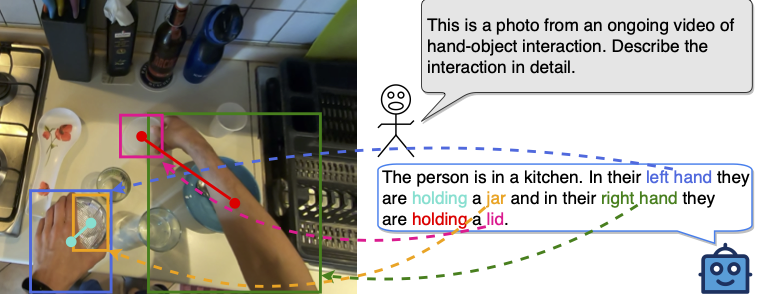
We propose the HOI-Ref task to understand hand-object interaction using Vision Language Models (VLMs). We introduce the HOI-QA dataset with 3.9M question-answer pairs for training and evaluating VLMs. Finally, we train the first VLM for HOI-Ref, achieving state-of-the-art performance.
Siddhant Bansal, Michael Wray, Dima Damen
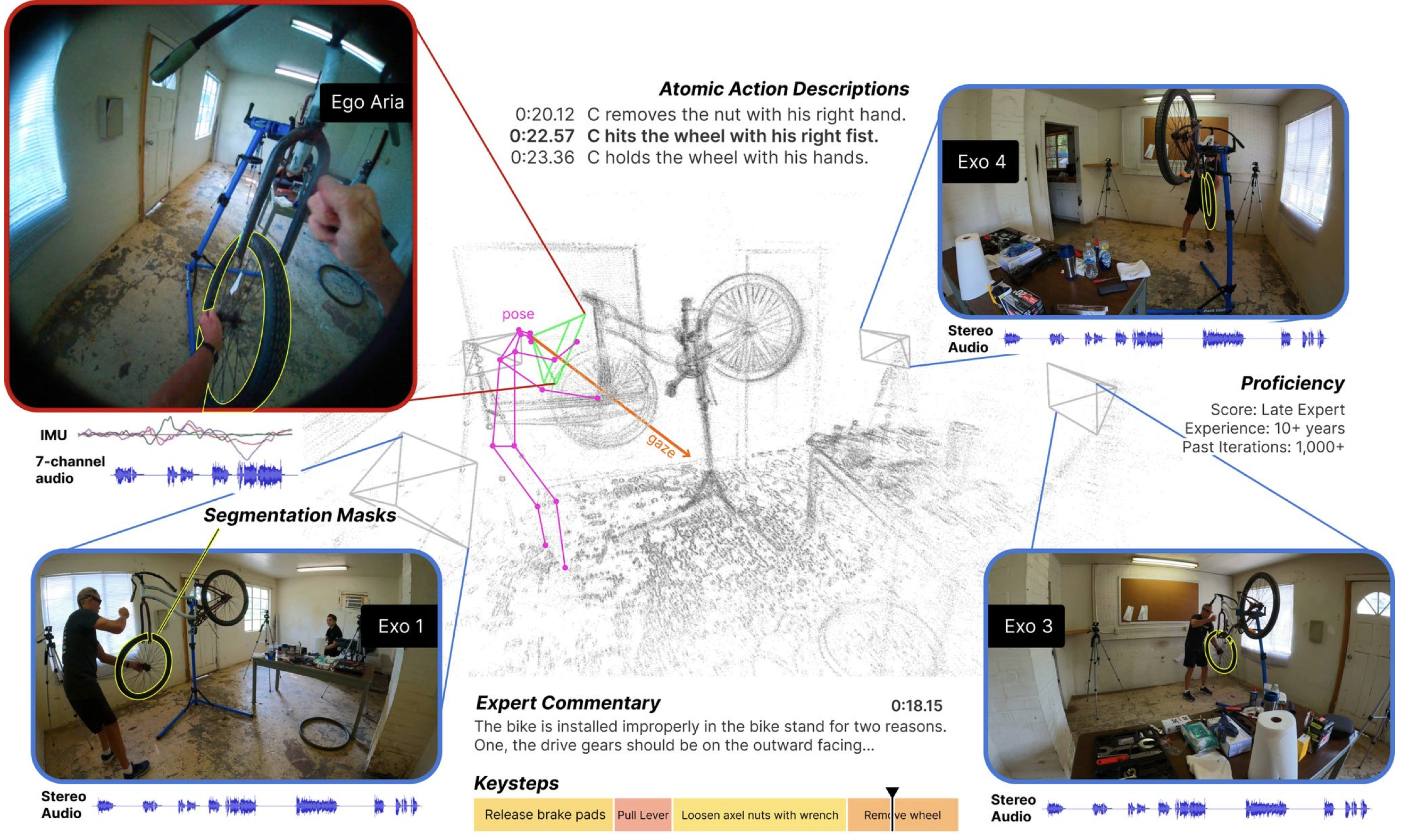
Ego-Exo4D is a diverse, large-scale multi-modal, multi-view, video dataset and benchmark collected across 13 cities worldwide by 839 camera wearers, capturing 1422 hours of video of skilled human activities.
We present three synchronized natural language datasets paired with videos. (1) expert commentary, (2) participant-provided narrate-and-act, and (3) one-sentence atomic action descriptions.
Finally, our camera configuration features Aria glasses for ego capture which is time-synchronized with 4-5 (stationary) GoPros as the exo capture devices.
Kristen Grauman, Andrew Westbury, Lorenzo Torresani, Kris Kitani, Jitendra Malik, Triantafyllos Afouras, Kumar Ashutosh, Vijay Baiyya, Siddhant Bansal, Bikram Boote, Eugene Byrne, Zach Chavis, Joya Chen, Feng Cheng, Fu-Jen Chu, Sean Crane, Avijit Dasgupta, Jing Dong, Maria Escobar, Cristhian Forigua, Abrham Gebreselasie, Sanjay Haresh, Jing Huang, Md Mohaiminul Islam, Suyog Jain, Rawal Khirodkar, Devansh Kukreja, Kevin J Liang, Jia-Wei Liu, Sagnik Majumder, Yongsen Mao, Miguel Martin, Effrosyni Mavroudi, Tushar Nagarajan, Francesco Ragusa, Santhosh Kumar Ramakrishnan, Luigi Seminara, Arjun Somayazulu, Yale Song, Shan Su, Zihui Xue, Edward Zhang, Jinxu Zhang, Angela Castillo, Changan Chen, Xinzhu Fu, Ryosuke Furuta, Cristina Gonzalez, Prince Gupta, Jiabo Hu, Yifei Huang, Yiming Huang, Weslie Khoo, Anush Kumar, Robert Kuo, Sach Lakhavani, Miao Liu, Mi Luo, Zhengyi Luo, Brighid Meredith, Austin Miller, Oluwatumininu Oguntola, Xiaqing Pan, Penny Peng, Shraman Pramanick, Merey Ramazanova, Fiona Ryan, Wei Shan, Kiran Somasundaram, Chenan Song, Audrey Southerland, Masatoshi Tateno, Huiyu Wang, Yuchen Wang, Takuma Yagi, Mingfei Yan, Xitong Yang, Zecheng Yu, Shengxin Cindy Zha, Chen Zhao, Ziwei Zhao, Zhifan Zhu, Jeff Zhuo, Pablo Arbelaez, Gedas Bertasius, David Crandall, Dima Damen, Jakob Engel, Giovanni Maria Farinella, Antonino Furnari, Bernard Ghanem, Judy Hoffman, C. V. Jawahar, Richard Newcombe, Hyun Soo Park, James M. Rehg, Yoichi Sato, Manolis Savva, Jianbo Shi, Mike Zheng Shou, Michael Wray
Conference on Computer Vision and Pattern Recognition (CVPR), 2024
Paper / Project Page / Video / Meta blog post
We propose Graph-based Procedure Learning (GPL) framework for procedure learning. GPL creates novel UnityGraph that represents all the task videos as a graph to encode both intra-video and inter-videos context. We achieve an improvement of 2% on third-person datasets and 3.6% on EgoProceL.
Siddhant Bansal, Chetan Arora, C.V. Jawahar
Winter Conference on Applications of Computer Vision (WACV), 2024
Paper / Download the EgoProceL Dataset / Project Page / Video
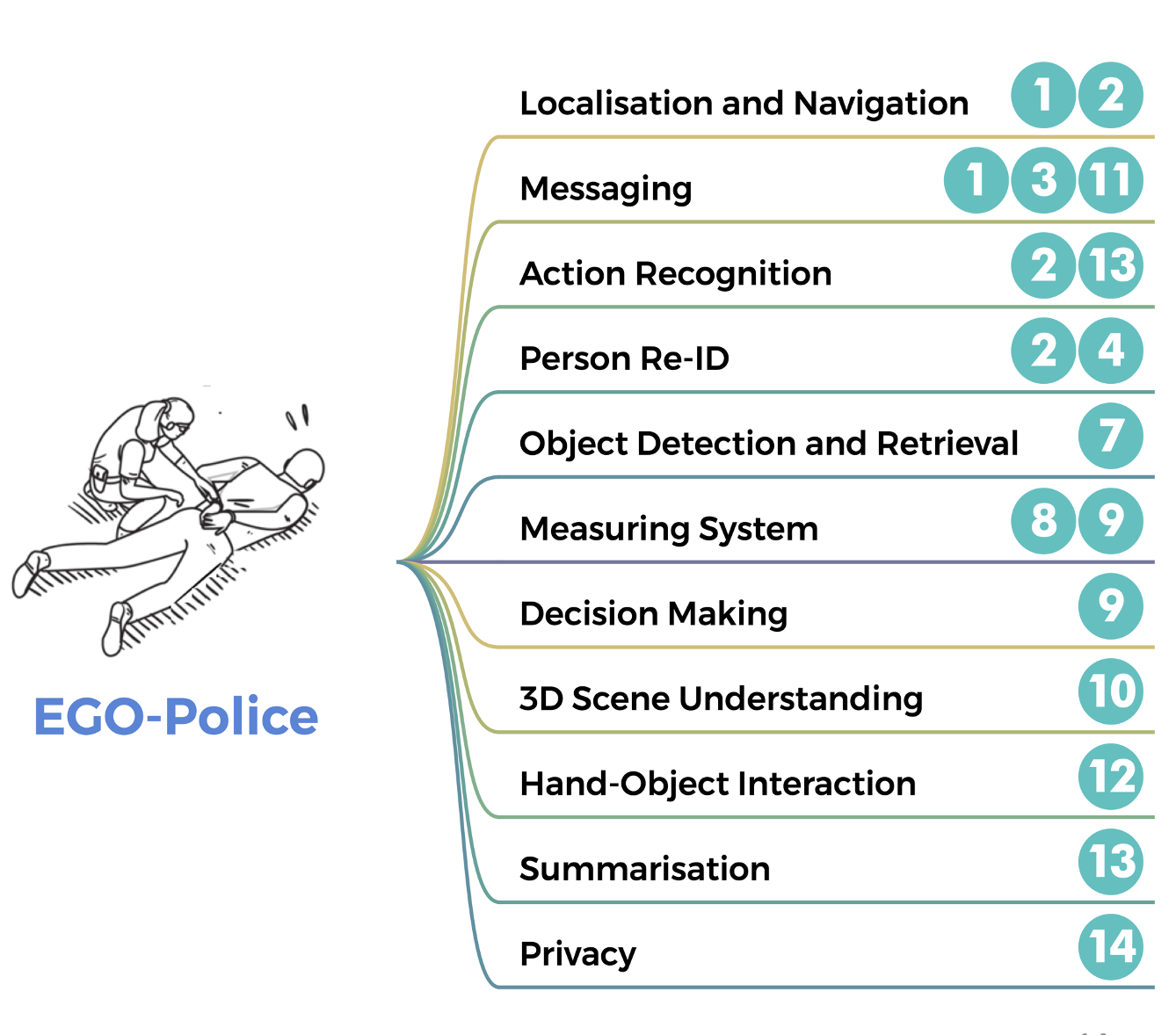
The survey looks at the difference between what we’re studying now in egocentric vision and what we expect in the future. We imagine the future using stories and connect them to current research. We highlight problems, analyze current progress, and suggest areas to explore in egocentric vision, aiming for a future that’s always on, personalized, and improves our lives.
Chiara Plizzari*, Gabriele Goletto*, Antonino Furnari*, Siddhant Bansal*, Francesco Ragusa*, Giovanni Maria Farinella, Dima Damen, Tatiana Tommasi
International Journal of Computer Vision (IJCV)
Project Page / Paper (IJCV) / Paper + comments (OpenReview) / Paper (arXiv)
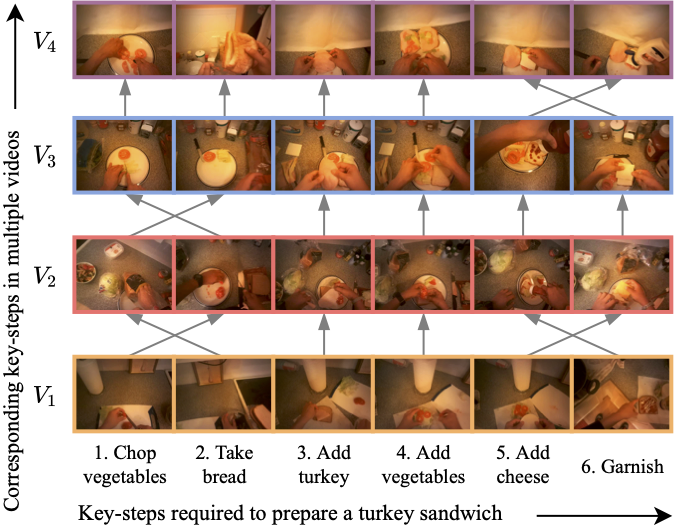
We propose the EgoProceL dataset consisting of 62 hours of videos captured by 130 subjects performing 16 tasks and a self-supervised Correspond and Cut (CnC) framework for procedure learning. CnC utilizes the temporal correspondences between the key-steps across multiple videos to learn the procedure.
Siddhant Bansal, Chetan Arora, C.V. Jawahar
European Conference on Computer Vision (ECCV), 2022
Paper / Download the EgoProceL Dataset / Project Page / Code
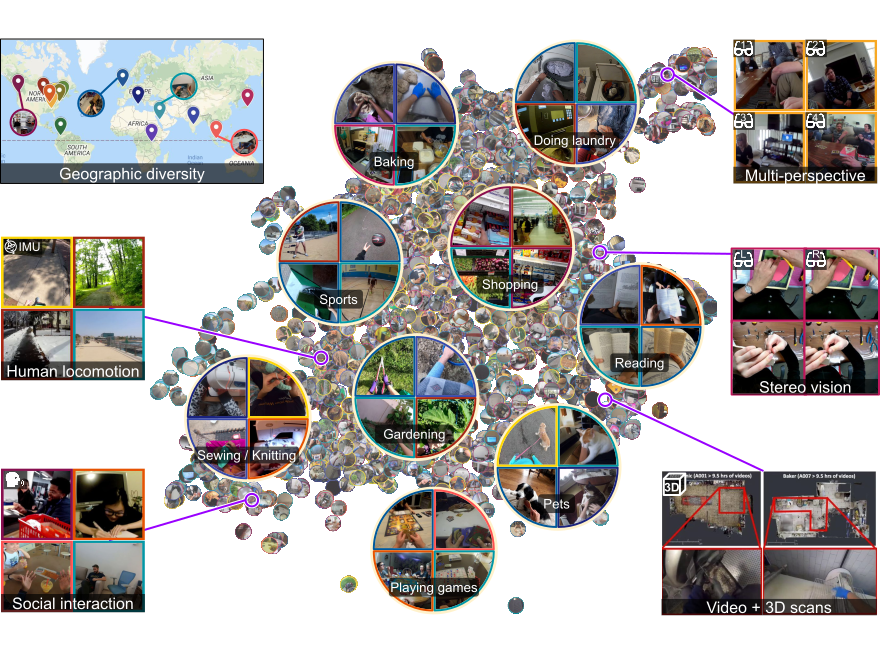
We offer 3,670 hours of daily-life activity video spanning hundreds of scenarios captured by 931 unique camera wearers from 74 worldwide locations and 9 different countries.
We present a host of new benchmark challenges centered around understanding the first-person visual experience in the past (querying an episodic memory), present (analyzing hand-object manipulation, audio-visual conversation, and social interactions), and future (forecasting activities).
Kristen Grauman, Andrew Westbury, Eugene Byrne, Zachary Chavis, Antonino Furnari, Rohit Girdhar, Jackson Hamburger, Hao Jiang, Miao Liu, Xingyu Liu, Miguel Martin, Tushar Nagarajan, Ilija Radosavovic, Santhosh Kumar Ramakrishnan, Fiona Ryan, Jayant Sharma, Michael Wray, Mengmeng Xu, Eric Zhongcong Xu, Chen Zhao, Siddhant Bansal, Dhruv Batra, Vincent Cartillier, Sean Crane, Tien Do, Morrie Doulaty, Akshay Erapalli, Christoph Feichtenhofer, Adriano Fragomeni, Qichen Fu, Christian Fuegen, Abrham Gebreselasie, Cristina Gonzalez, James Hillis, Xuhua Huang, Yifei Huang, Wenqi Jia, Weslie Khoo, Jachym Kolar, Satwik Kottur, Anurag Kumar, Federico Landini, Chao Li, Yanghao Li, Zhenqiang Li, Karttikeya Mangalam, Raghava Modhugu, Jonathan Munro, Tullie Murrell, Takumi Nishiyasu, Will Price, Paola Ruiz Puentes, Merey Ramazanova, Leda Sari, Kiran Somasundaram, Audrey Southerland, Yusuke Sugano, Ruijie Tao, Minh Vo, Yuchen Wang, Xindi Wu, Takuma Yagi, Yunyi Zhu, Pablo Arbelaez, David Crandall, Dima Damen, Giovanni Maria Farinella, Bernard Ghanem, Vamsi Krishna Ithapu, C. V. Jawahar, Hanbyul Joo, Kris Kitani, Haizhou Li, Richard Newcombe, Aude Oliva, Hyun Soo Park, James M. Rehg, Yoichi Sato, Jianbo Shi, Mike Zheng Shou, Antonio Torralba, Lorenzo Torresani, Mingfei Yan, Jitendra Malik
Conference on Computer Vision and Pattern Recognition (CVPR), 2022 (ORAL; Best paper finalist [link])
Paper / Project Page / Video / Benchmark’s description / EPIC@ICCV2021 Ego4D Reveal Session
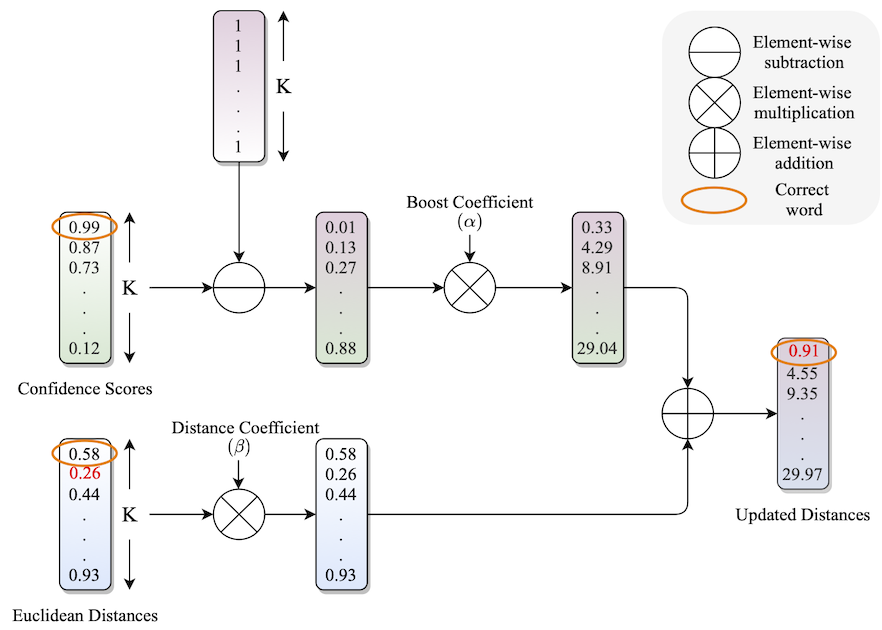
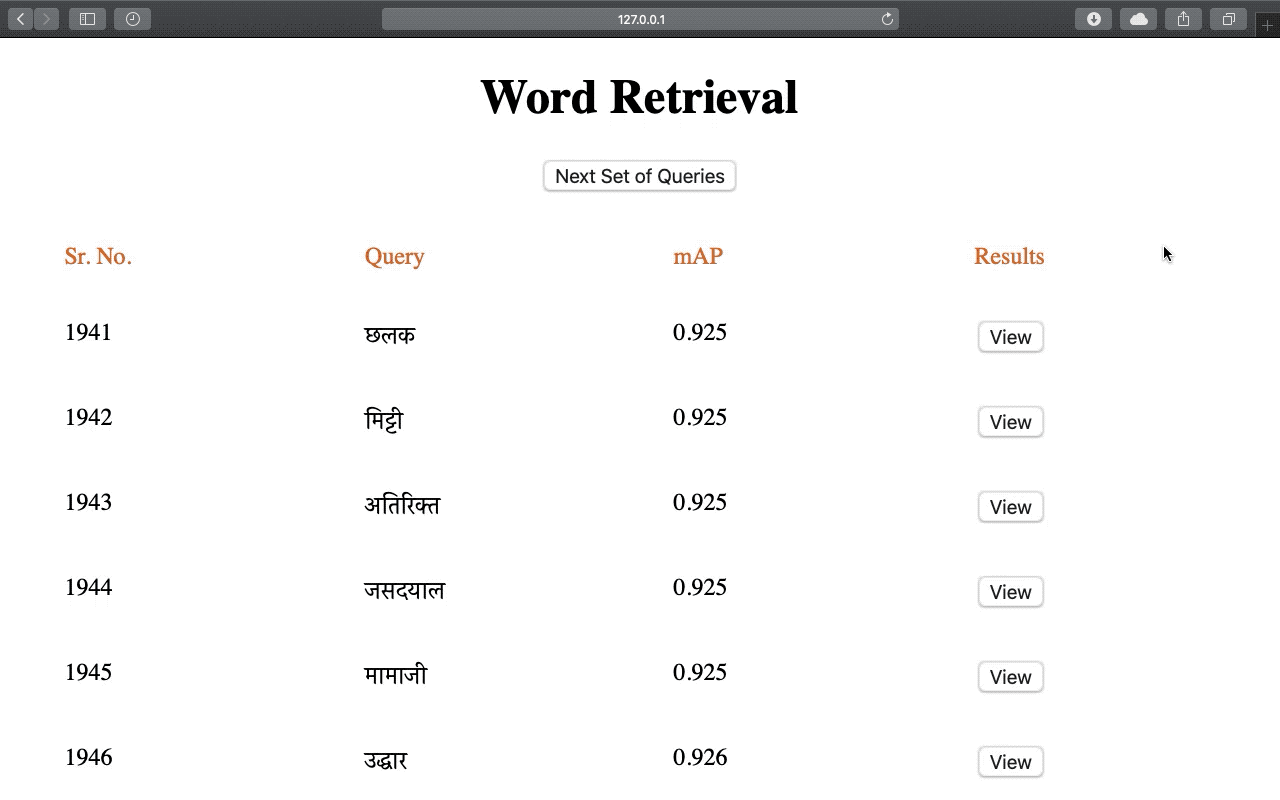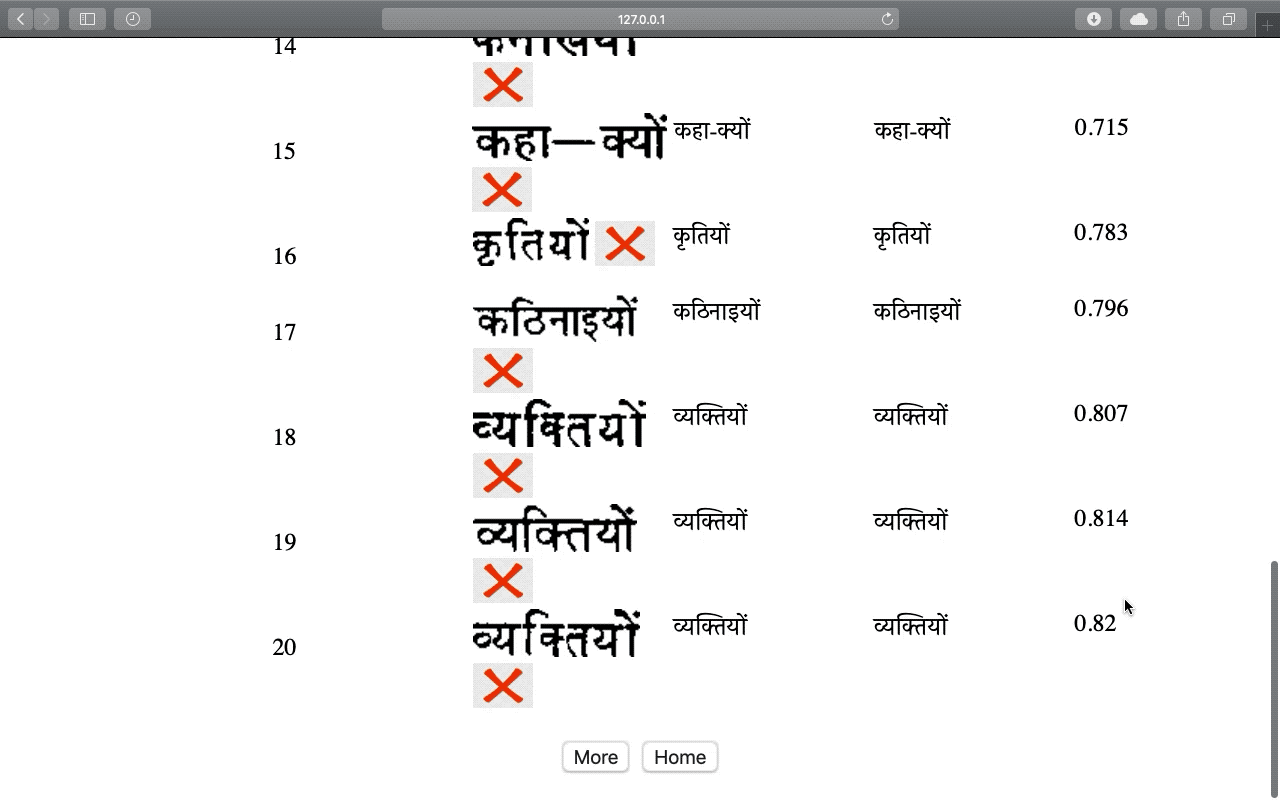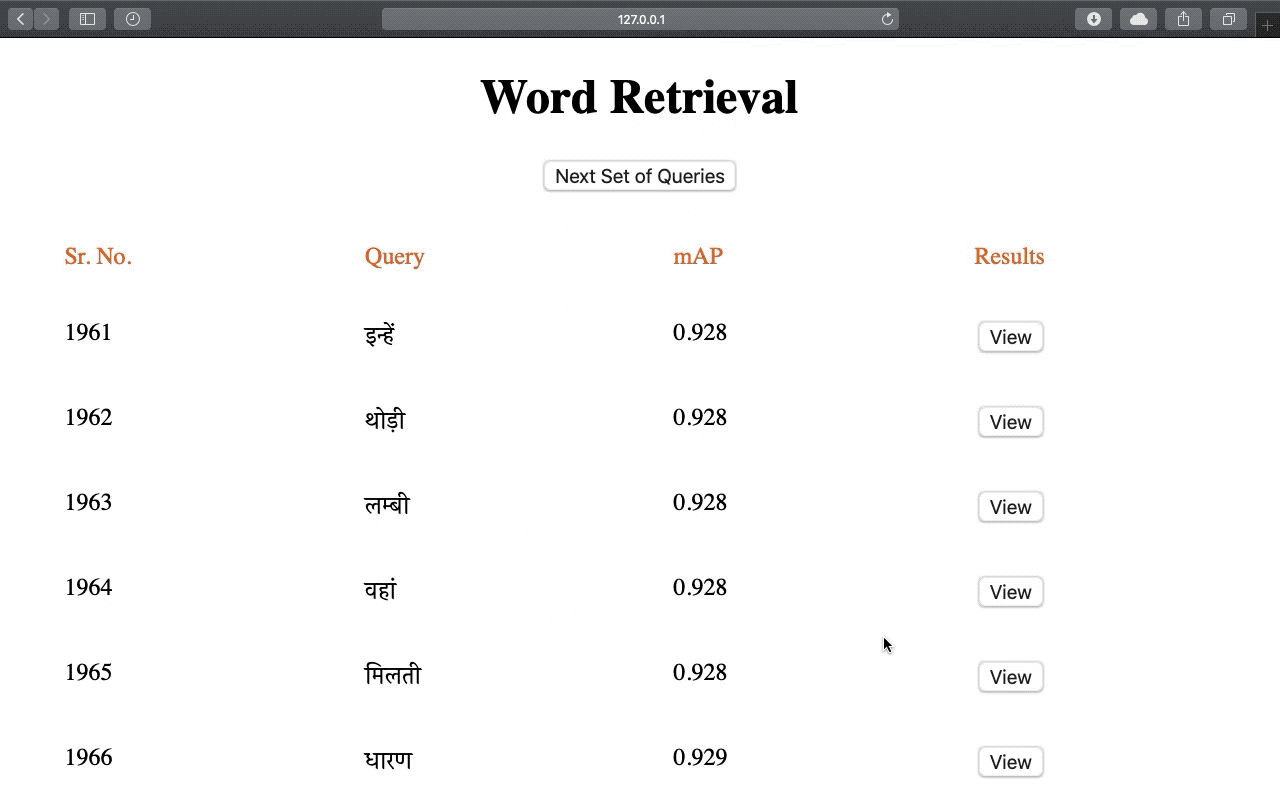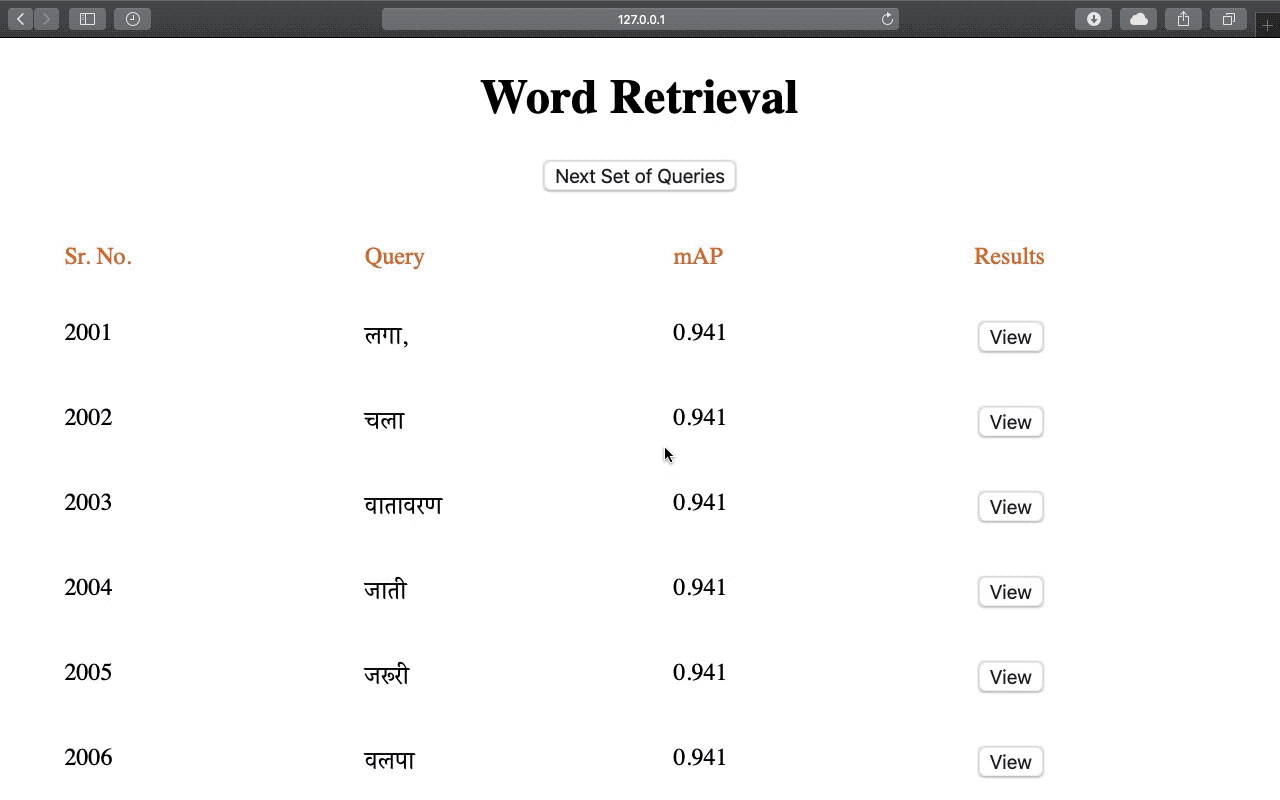
We propose to fuse recognition-based and recognition-free approaches for word recognition using learning-based methods.
Siddhant Bansal, Praveen Krishnan , and C.V. Jawahar
International Conference on Pattern Recognition (ICPR), 2020
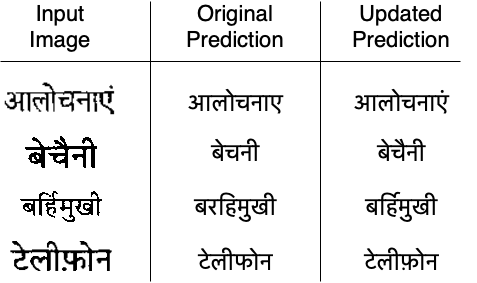
Fusing recognition-based and recognition-free approaches using rule-based methods for improving word recognition and retrieval.
Siddhant Bansal, Praveen Krishnan , and C.V. Jawahar
IAPR International Workshop on Document Analysis and System (DAS), 2020 (ORAL)
Paper / Demo / Project Page / Code (Github) / Poster
{kind=link}