Improving Word Recognition using Multiple Hypotheses and Deep Embeddings
Siddhant Bansal Praveen Krishnan C.V. Jawahar
Abstract
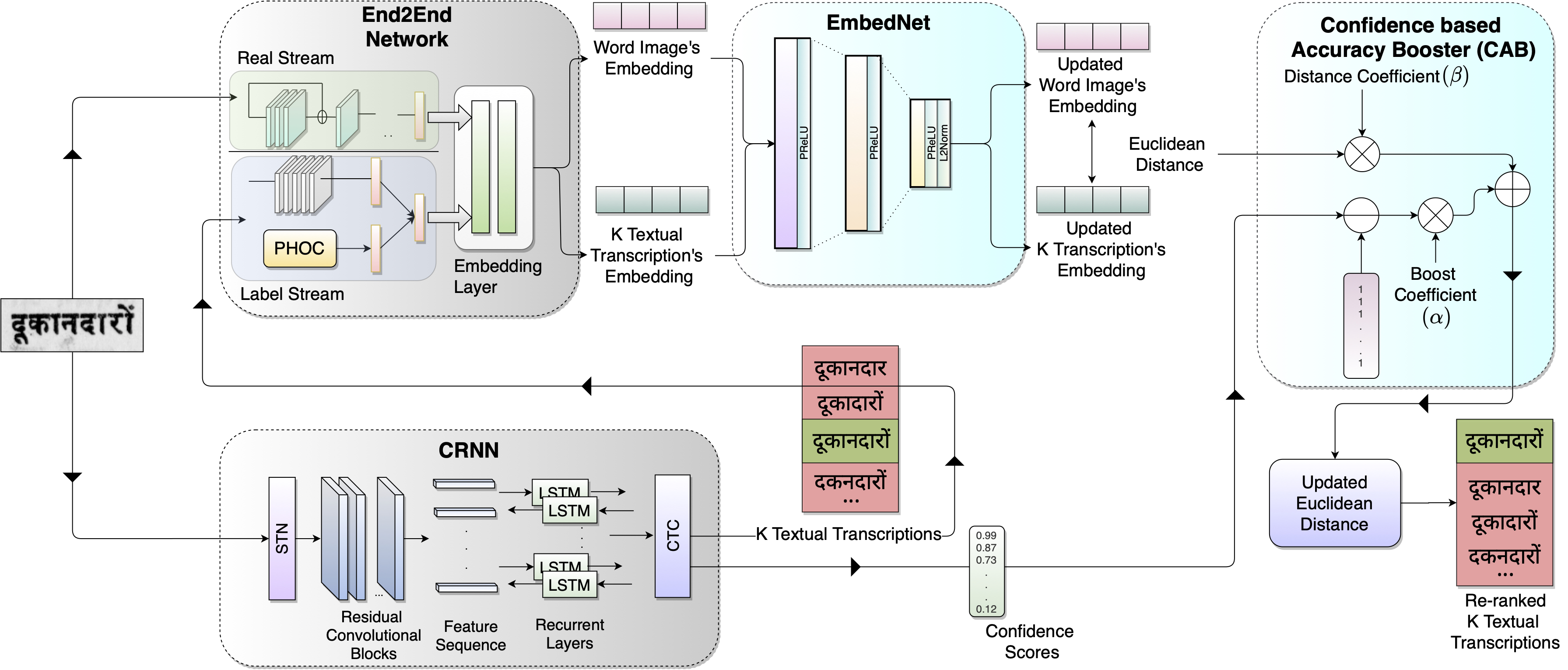
We propose to fuse recognition-based and recognition-free approaches for word recognition using learning-based methods. For this purpose, results obtained using a text recognizer and deep embeddings (generated using an End2End network) are fused. To further improve the embeddings, we propose EmbedNet, it uses triplet loss for training and learns an embedding space where the embedding of the word image lies closer to its corresponding text transcription’s embedding. This updated embedding space helps in choosing the correct prediction with higher confidence. To further improve the accuracy, we propose a plug-and-play module called Confidence based Accuracy Booster (CAB). It takes in the confidence scores obtained from the text recognizer and Euclidean distances between the embeddings and generates an updated distance vector. This vector has lower distance values for the correct words and higher distance values for the incorrect words. We rigorously evaluate our proposed method systematically on a collection of books that are in the Hindi language. Our method achieves an absolute improvement of around 10% in terms of word recognition accuracy.
Paper
Please consider citing if you make use of this work and/or the corresponding code:
@misc{bansal2020improving,
title={Improving Word Recognition using Multiple Hypotheses and Deep Embeddings},
author={Siddhant Bansal and Praveen Krishnan and C. V. Jawahar},
year={2020},
eprint={2010.14411},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
Code
This work is implemented using the pytorch neural network framework.
The code is available on GitHub. Link: https://github.com/Sid2697/Word-recognition-EmbedNet-CAB
Video