HOI-Ref: Hand-Object Interaction Referral in Egocentric Vision
Siddhant Bansal Michael Wray Dima Damen
Paper Dataset Code Demo (coming soon)
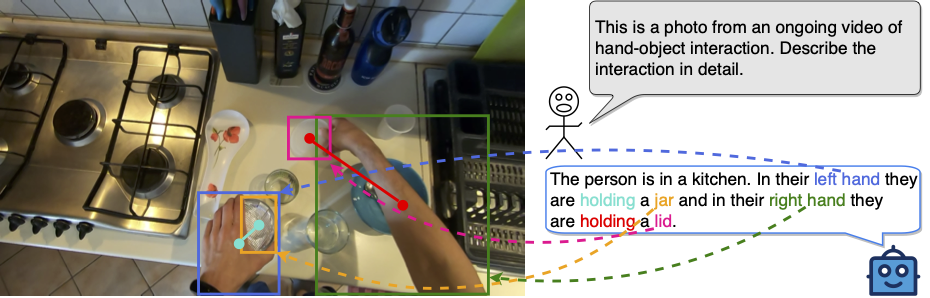
What is Hand-Object Interaction Referral?
VLM4HOI: VLM for Hand-Object Interaction Referral
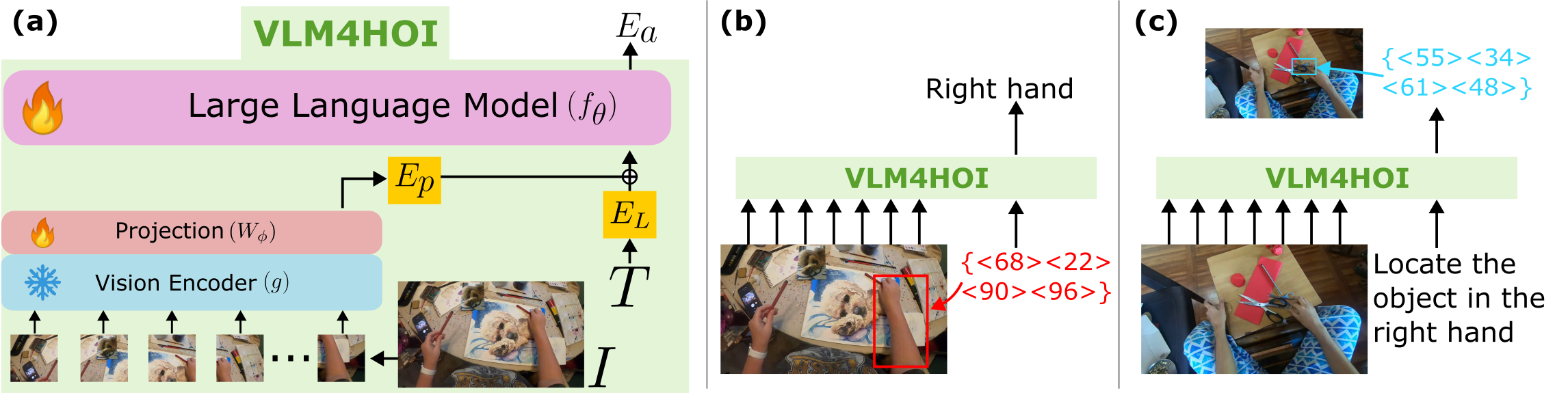
HOI-Ref Task

HOI-QA Dataset
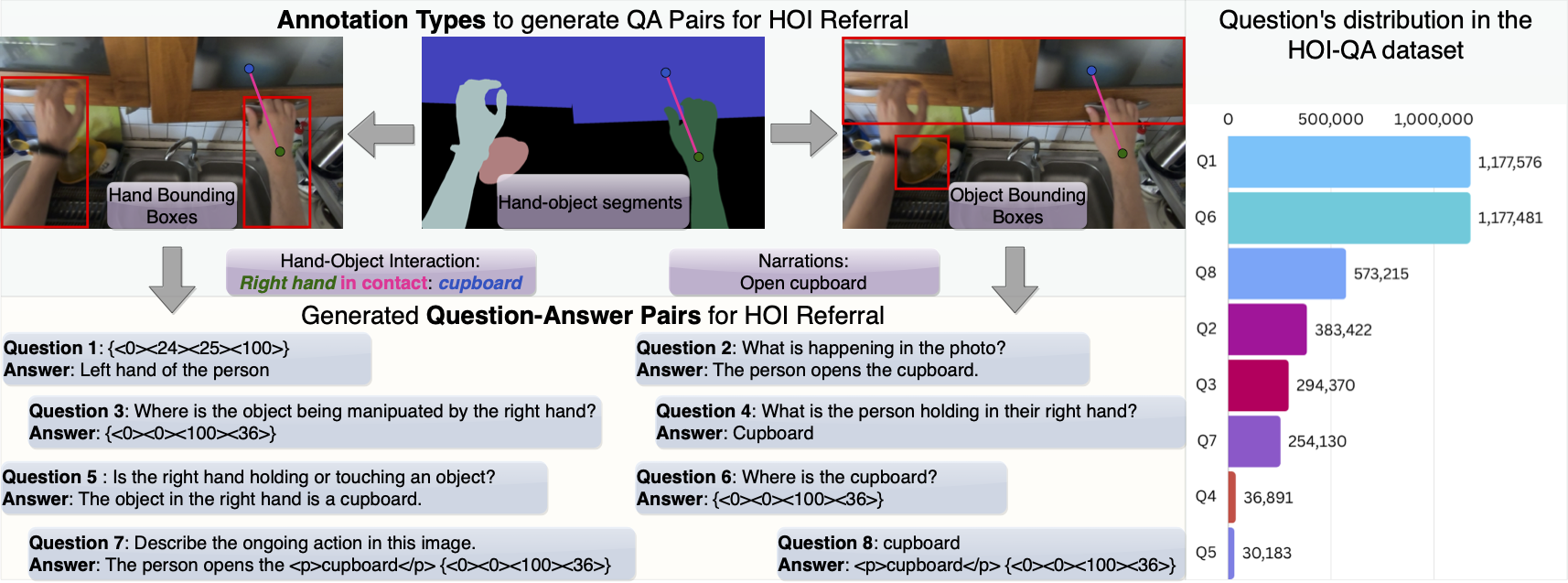
Details on downloading the dataset can be found on GitHub.
Qualitative Results

Paper
Code and Dataset
The code for this work is available on GitHub!
Link: https://github.com/Sid2697/HOI-Ref
The HOI-QA dataset is available on GitHub!
Link: https://github.com/Sid2697/HOI-Ref/blob/main/hoiqa_dataset/HOIQA_README.md
Acknowledgements
This work uses public datasets—code and models are publicly available. The research is supported by EPSRC UMPIRE EP/T004991/1 and EPSRC Programme Grant VisualAI EP/T028572/1. S Bansal is supported by a Charitable Donation to the University of Bristol from Meta. We acknowledge the use of the EPSRC funded Tier 2 facility JADE-II EP/T022205/1. The authors would like to thank Alexandros Stergiou, Kranti Kumar Parida, Samuel Pollard, and Rhodri Guerrier for their comments on the manuscript.
Please consider citing if you make use of the work:
@article{bansal2024hoiref,
title={HOI-Ref: Hand-Object Interaction Referral in Egocentric Vision},
author={Bansal, Siddhant and Wray, Michael, and Damen, Dima},
journal={arXiv preprint arXiv:2404.09933},
year={2024}
}