Deep Future Gaze: Gaze Anticipation on Egocentric Videos Using Adversarial Networks
This paper proposes a Generative Adversarial Network (GAN) based architecture called Deep Future Gaze (DFG) for addressing the task of gaze anticipation in egocentric videos. DFG takes in a single frame and generates multiple frames; it attempts to anticipate the future gazes in the generated multiple frames. As in the case of other GANs, DFG consists of two networks: Generator (GN) and Discriminator (D). Here, GN is a two-stream architecture (using 3D-CNN) which attempts to untangle the foreground and background to generate the future frames, whereas, D differentiates the synthetic frames generated by GN from the real frames, thereby, helping to improve GN. This enables DFG to perform better than the rest of the state-of-the-art techniques.
Architecture Overview
The following figure gives an overview of DFG. It consists of two networks: Generator Network (GN) and the Discriminator Network (D). GN is further divided into: Future Frame Generation Module (G) and Temporal Saliency Prediction Module (GP).
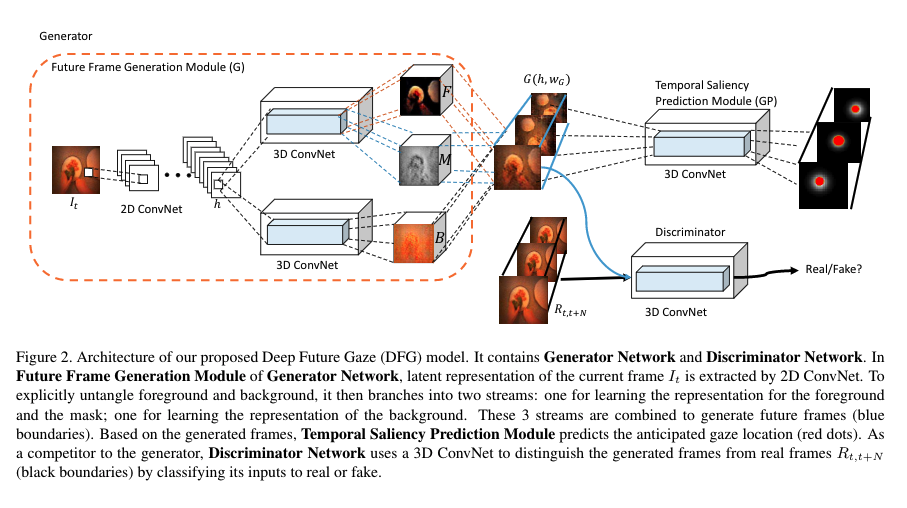
The Generator Network
For differentiating between the foreground (hands and objects) and background motion (complex head motion), the authors propose to use a two-stream architecture for GN. Here, each stream consists of a 3D Convolutional Neural Network (CNN) architecture.
The input frame is first passed through a 2D-CNN for generating a latent representation. As shown in the figure above, this representation is then provided as an input to both the streams of the two-stream architecture. The two-stream architecture consists of foreground and background generation model. Both the streams generate N future frames. In addition to generating the foreground frames, the foreground model also generates the spatial temporal mask which has a pixel range of [0, 1]. Here, 1 indicates foreground and 0 indicates background. The background generation model has its own independent 3D-CNN, which, as the name suggests, generates the background frames. For preserving the spatial and temporal information, the authors add up-sampling layers after the convolution layers.
For looking real, the synthetic frames have to satisfy two criteria:
- Coherent semantics across the frames (e.g. no table surface is inside the refrigerator);
- Consistent motion across time (e.g. hand motions should be smooth across the frames).
Authors use GP which uses the foreground, background, and mask frames for anticipating the gaze location (shown using red dot in the figure above).
The Discriminator Network
D aims at distinguishing the synthetic examples from the real ones. It follows the same architecture as G, however, the up-sampling layers in G are replaced by convolutional layers. The output of D is a binary label indicating whether the input is real or not.
Training Details
Following the concept of Generative Adversarial Network (GAN), the authors make G and D play against each other. Task of G is to generate future frames which can fool D, while D’s task is to identify the real frames. In order to generate a frame consistent with the input frame, the authors use L1 loss. Both the networks are trained alternatively. The objective function of D consists of a combination of binary cross entropy loss. However, G has to satisfy two requirements: a) real output for fooling D; b) initial frame should be visually consistent with the input frame. For that, a combination of binary cross entropy loss and L1 loss is used (mean square error loss results in over-smoothing of the first generated frame). GP is trained using Kullback divergence (KLD) loss in a supervised approach.
Conclusions
The authors test DFG on GTEA, GTEAPlus, and OST datasets. For analysis, authors use Area Under the Curve (AUC) and Average Angular Error (AAE) metrics.
Some of the important observations are:

- Images in the figure above show that DFG was able to untangle foreground and background motions. In the foreground, both hand and objects are highlighted, whereas, the background is uniform all the time. And the mask highlight highest activation point;
- Without using egocentric cues such as hands and objects of interest, DFG works better that the state-of-the-arts, which, in many cases, use egocentric cues;
- Using two-steam architecture for learning foreground and background information, improves the gaze anticipation accuracy;
- GP trained only on real frames does not perform well;
- Gaze moment on individual frames is dependent on their previous states;
- DFG is successful in learning egocentric cues in the spatial domain and motion dynamics in the temporal domain.