First Person Action Recognition Using Deep Learned Descriptors
This paper proposes a three-stream convolutional neural network architecture for the task of action recognition in first-person videos. The three streams consist of the spatial, temporal, and Ego streams. The Ego stream is a two-stream architecture consisting of 2D and 3D CNN; it takes in hand mask, head motion, and saliency map for generating the class scores. The Ego stream when combined with the spatial and temporal streams, achieves a 10% gain in the action recognition accuracy.
Ego ConvNet
Following diagram shows the two-stream Ego ConvNet architecture for learning features specific to egocentric videos.
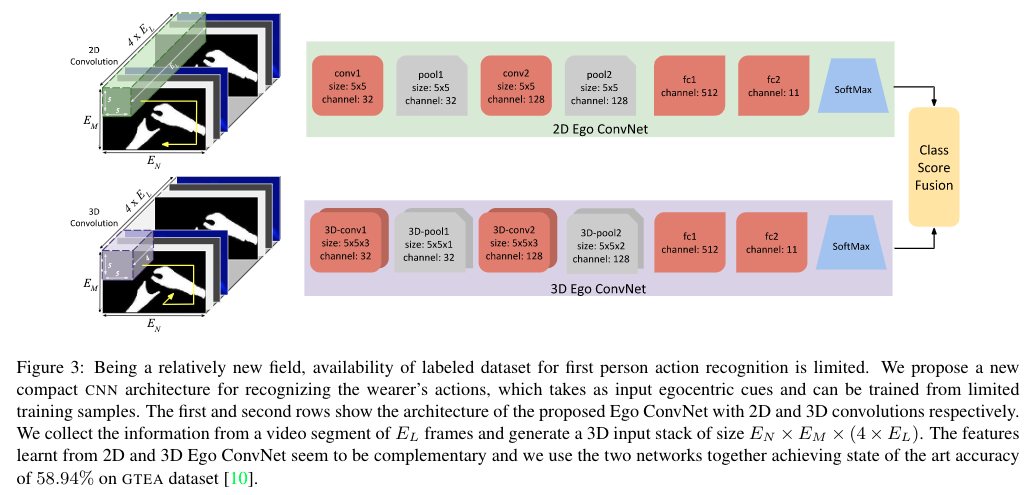
The authors use three different input modalities for the Ego ConvNet:
- Hand Mask;
- Head Motion;
- Saliency map.
Hand Mask
For generating the hand mask, authors model local appearance and global illumination. Local textures for different illumination conditions are captured using 48 Gabor filters. On the other hand, the authors perform k-means clustering on the HSV color space images’ histograms for learning the global features. Then for each cluster, the authors train a random tree regressor. The figure below shows some of the generated masks.

Head Motion
The authors attempt to create a framework that relies only on one sensor: camera. So, in order to avoid using an eye tracker for the gaze information, the authors assume that, if the camera wearer is looking straight, then the head motion is approximately similar to the gaze information. This motivates them to capture the head motion using 2D homography transformation of the image.
Saliency Map
If the camera is static, then by using the optical flow information one can easily find out the object being handled by the camera wearer. However, in the case of egocentric videos, the camera is not static. To compensate for that and to avoid using additional sensors, the authors use 2D homography for canceling the head motion in the image. Doing this highlights the dominant motion in the scene. Which in most of the cases is the object which is being manipulated using the hands.
Architecture
The first figure on this webpage shows the architecture of the Ego ConvNet. It consists of 2D and 3D convolutional networks. The authors use this architecture for learning the coordination actions between hands, head motion, and saliency maps. The inputs to this network are:
- Hand mask: As binary image;
- Camera motion: Both x and y direction as grayscale images;
- Saliency map: As grayscale image. Authors use infogain multinomial logisitc for training the network.
Three-stream Architecture
The authors experiment by combining the learned Ego ConvNet with the spatial and temporal stream as shown in the figure below. By using this architecture, they are able to improve the action recognition accuracy by 10%.

Conclusions
The authors achieve state-of-the-art results on GTEA, CMU Kitchens, ADL, and UTE. As GTEA is a small dataset, the authors also train the network on the Interactive Museums dataset.
Some of the important observations are:
- 2D and 3D network alone as Ego ConvNet shows similar performance;
- Fusing 2D and 3D network as a two-stream archiecture results in performace gains;
- Further fusing them with spatial and temporal streams, the authors were able to improve action recognition accuracy by 10%;
- The proposed network improves upon the state-of-the-art on all the four datasets.
Here are some of the samples of correctly classified examples:
