Two-Stream Convolutional Networks for Action Recognition in Videos
This paper proposes a two-stream convolutional neural network architecture for the task of action recognition in a video. Out of the two streams, the spatial stream uses frames from a video and learns the spatial information, whereas, the temporal stream uses a stack of optical flow images for learning the temporal information. The information from both of these networks is combined to predict the final output. The authors analyze various inputs to the temporal network and use multitask learning for improving the performance of the architecture.
Methodology
The following figure shows the proposed two-stream architecture for video recognition.
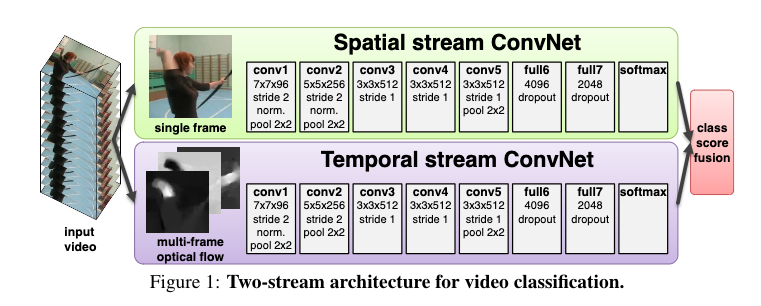
As seen, it has two different input streams, the spatial stream and the temporal stream. The spatial stream takes in a single frame from the video and generates the class scores, whereas, the temporal stream takes in a stack of optical flow images and generates the class scores. These classes scores are later fused together to generate the final score.
Optical flow ConvNets
- Using stacked optical flow images as an input to the temporal stream eliminates the need to estimate motion implicitly.

As shown in the figure above, various input configurations can be used for representing the optical flow. They are:
- Dense optical flow, are a set of displacement vectors between the pairs of consecutive frames;
- Trajectory stacking, samples the same location across several frames sampled across the motion trajectories;
- Bi-directional optical flow, uses an additional set of flow fields in the opposite direction;
- Mean flow subtraction approach subtracts mean vector from a displacement field.
Evaluation and Conclusions
The authors evaluate the two-stream architecture on UCF-101 and HMDB-51 dataset.
Major conclusions/observations:
- Training the spatial CNN solely on UCF-101 leads to over-fitting. However, fine-tuning the network or training the last layer achieves a better performance;
- Using multiple optical flow images is useful as they provide a long term motion information;
- Using different stacking techniques generate similar results;
- Using bi-directional flow images for training the CNN is not useful;
- Temporal net performs the best when it is trained using multitask learning.
- Using a stack of RGB frames for the temporal information performs worse as compared to the case when using the optical flow images;
- The authors conclude that the information in the temporal and spatial stream is complementary, as fusing them significantly improves the accuracy;