Going Deeper into First-Person Activity Recognition
This paper aims at improving action recognition accuracy in the egocentric videos by using a two-stream Convolutional Neural Network (CNN) architecture. Here, one stream learns the appearance information, whereas the other stream learns the motion information. The two-stream CNN proposed is able to capture the object attributes and hand-object configurations.
Methodology (Egocentric Activity Deep Network)
For a given video sequence, the task here is to predict object, action, and activity labels. For this task a two-stream CNN is used. The two-streams are divided as: (a) ObjectNet and (b) ActionNet.
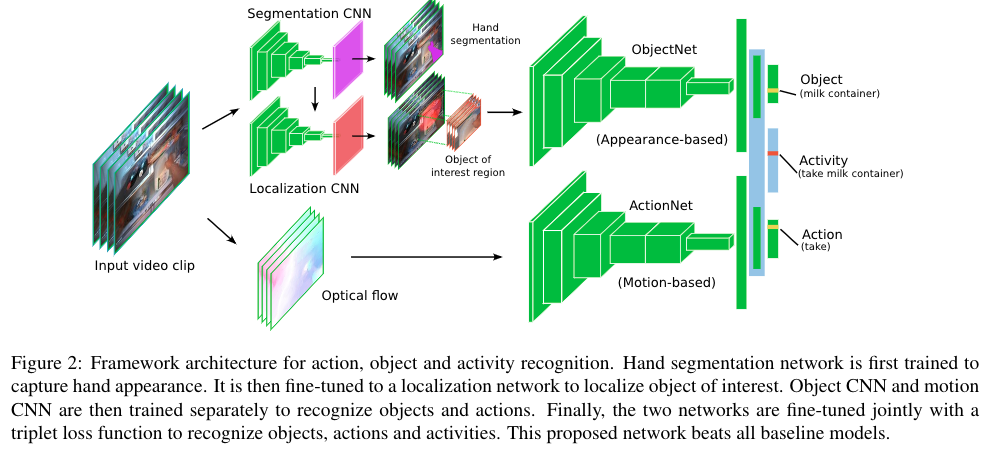
ObjectNet: Recognizing Objects from Appearance
The aim of object net is to predict the object’s label. For this purpose, the authors train a pixel-to-pixel hand segmentation network for generating a hand probability map. And the the authors also train a pixel-to-pixel object localization network for predicting the location of the object of interest (object with which the subject is interacting). Once the segmentation network is trained, the layers from it form the top layer of the object localization network. Which are later fine-tuned for localizing the objects. This biases the network to use hand’s presence for predicting the object of interest’s location. Using the probability map from the localization network, the objects of interest are cropped from the image and passed through the CNN trained for recognizing objects.
ActionNet: Recognizing Actions from Motion
The aim of ActionNet is to predict the action’s label. Here the authors use a CNN for capturing foreground (hand and object) and background (camera motion) information. For this purpose, the authors use a stack of optical flow images for training the ActionNet.
Fusion Layer: Recognizing Activity
Once the encoding from the ObjectNet and ActionNet are generated, they are needed to be fused for predicting the final activity label. For this purpose, the authors propose to concatenate the second last fully-connected layer from both the network and adding a new fully-connected network on the top of it. The final network has three losses: action, object, and activity loss. For calculating the final loss, a weighted sum of the three loss is calculated.
Experiments and Conclusions
The authors evaluate the proposed methods on: GTEA, GTEAGaze, and GTEAGazePlus. They conclude that:
- Hands are important for object recognition;
- Object attributes are important for object recognition;
- Motion network is capable of automatically identifying the foreground and learning the complex camera motion information;
- Motion network is capable of learning the temporal motion patters of the objects/subject;
- Object localization is crucial for activity recognition;
- Jointly training all the three networks performs better as compared to SVM fusion of the two networks.